
Using Python to Pay Parking Tickets
09 Feb 2014Using Python to Pay Parking Tickets
An enterprising fellow from Milwaukee built a site to automatically pay parking tickets in his city and in Madison. Unfortunately, the city of Madison changed around their ticket-payment website, so the site is not working. I thought it would be a good programing challenge for me.
How Do You Work with Web Services When They Have No API?###
Since the City of Madison doesn’t have an API on their website, it’s not a simple matter of sending a query and getting back a nicely-formatted JSON response to use in my app. So how can I get the information that I need from the website?
Fortunately, all websites have at least one available point of entry - via the web, as a user! There’s a Python package to emulate user behavior in a browser and return the HTTP response, which we can further manipulate as we want.
This is Mechanize, originally developed for Perl. I install the Python package and make a script to go to the City of Madison’s parking ticket payment site at https://www.cityofmadison.com/epayment/parkingTicket/. I based this on an example at http://stockrt.github.io/p/emulating-a-browser-in-python-with-mechanize/.
import os
import sys
import mechanize
import cookielib
# Browser
br = mechanize.Browser()
# Cookie Jar
cj = cookielib.LWPCookieJar()
br.set_cookiejar(cj)
# Browser options
br.set_handle_equiv(True)
br.set_handle_redirect(True)
br.set_handle_referer(True)
br.set_handle_robots(False)
# Follows refresh 0 but not hangs on refresh > 0
br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor(), max_time=1)
# Want debugging messages?
#br.set_debug_http(True)
#br.set_debug_redirects(True)
#br.set_debug_responses(True)
# User-Agent (this is cheating, ok?)
br.addheaders = [('User-agent', 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1')]
# Open some site, let's pick a random one, the first that pops in mind:
r = br.open('https://www.cityofmadison.com/epayment/parkingTicket/search.cfm')
html = r.read()
# Show the source
#print htmlThis returns us the html of the city’s parking ticket page as a big string of HTML.
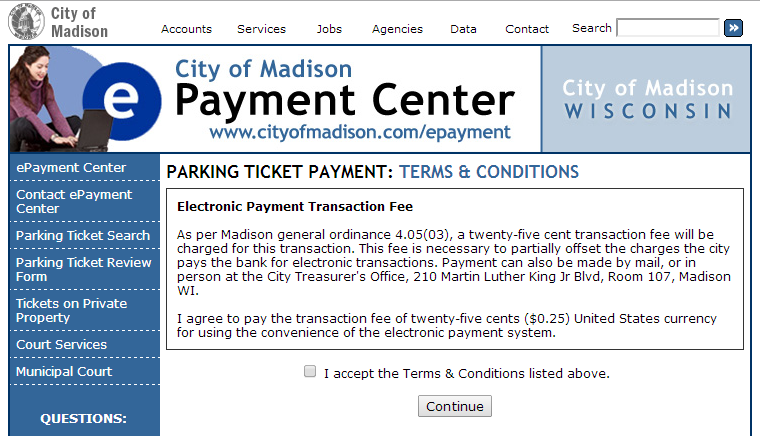
Searching for Tickets##
In order to search for a parking ticket, it looks like I need to first accept the terms and continue.
Since Mechanize is ‘stateful’ - it acts like a browser tab that a user would have open - I can submit this form and continue working with my browser class.
Before we do that, here are some other things you can do with Mechanize:
# Show the source
#print html
# or
print br.response().read()
# Show the html title
print br.title()
# Show the response headers
print r.info()
# or
print br.response().info()
#Show the available forms
for f in br.forms():
print f
print '\n'Back to the main objective. We need to first:
- Find the form on the page with the checkbox
- Select the checkbox
- Submit the form to continue
#fet First hurdle: Accepting the terms. Here we find a form, click a checkbox, and submit the form to load the next page into mechanize
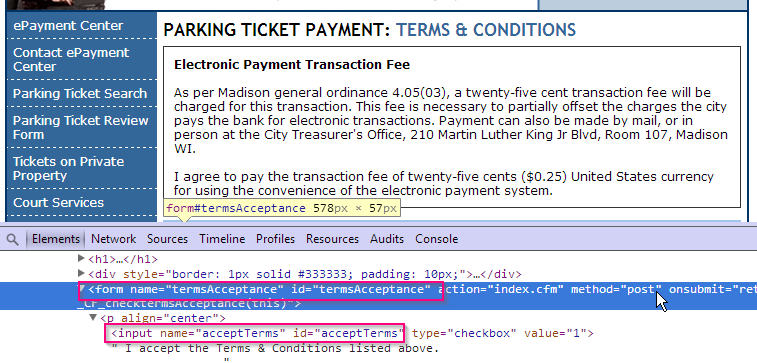
br.select_form(name='termsAcceptance')
br.find_control(name="acceptTerms").value = ["1"]
br.submit()In order to do this, I needed to find the name of the form and the checkbox control. I used Chrome Developer tools to inspect it:
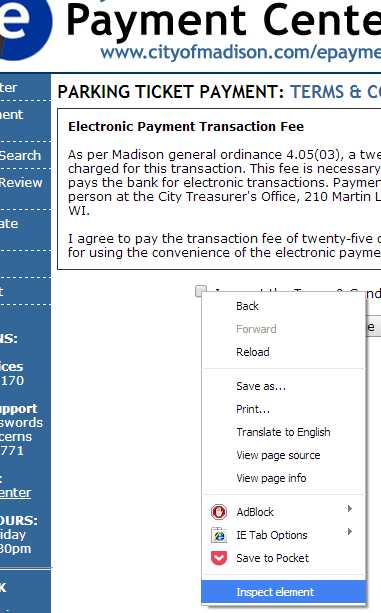
So we follow that action in our simulated browser and are brought to the Search page:
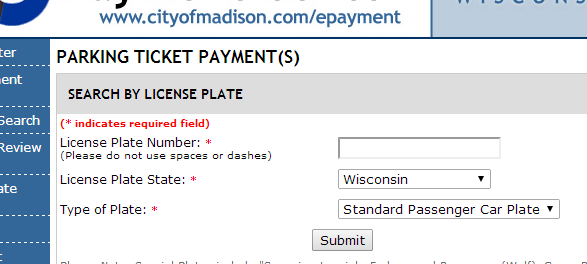
Great news! This is where we can enter our first dynamic input - a license plate to test. I do a similar inspection and find the names of the form and controls I need to manipulate:
br.select_form(name='plateSearch')
br.find_control(name="Plate").value = '123ABC'
br.find_control(name="State").value = ["WI"]
br.find_control(name="VehTyp").value = ["PC"]
br.submit()
text = br.response().read()
#fet For inspection, we can write the text of the page that loads to a file
with open('msnticketresponse.html', 'wb') as f:
f.write(text)
f.close()Here’s what the HTML of the search returns for a plate with existing tickets:
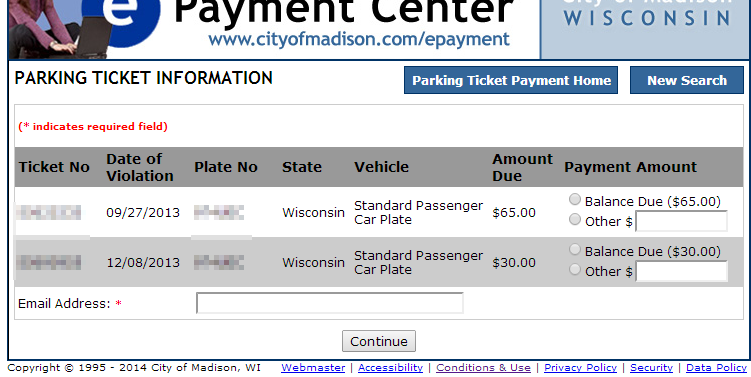
Manipulating the HTML Search Results to Work With Them in Python
We need to take the HTML output and parse the page. The problem is that the output is not always regular. We need something like regular expressions that will let us recognize certain, sometimes repeated parts of the page.
The LXML library is a good starting place to process XML and HTML in Python.
We’ll also take advantage of XPATH, which is like regex for XML: Let’s inspect the HTML of the search results to find what is regular about these ticket results. I’ve skipped over the header of the page and gone right to the meat of where the tickets are:
<table id="main" cellspacing="0">
<tr>
<td colspan="2"><img src="/images/ePayment.jpg" width="740" height="106"></td>
</tr>
<tr>
<td id="sidebar">
<!-- InstanceBeginEditable name="Sidebar" -->
<!-- InstanceEndEditable -->
</td>
<td id="content">
<!-- InstanceBeginEditable name="Content" -->
<h1 style="float:left;">Parking Ticket Information</h1>
<div style="float:right;margin-bottom:10px;"><a class="linkButton" href="index.cfm" style="width:200px;">Parking Ticket Payment Home</a> <a class="linkButton" href="search.cfm" style="width:100px;">New Search</a></div>
<br clear="all" />
<form name="Payments" id="Payments" action="ticketPayments.cfm" method="post" onsubmit="return _CF_checkPayments(this)">
<table cellpadding="0" cellspacing="0" border="0" width="100%" style="border: 1px solid #CCCCCC;">
<tr>
<td colspan="7" class="RequiredLabel"><br>(* indicates required field)<br><br></td>
</tr>
<tr class="backgroundMedium">
<td class="Heading14Bold" width="12%">Ticket No</td>
<TD class="Heading14Bold" width="12%">Date of Violation</TD>
<TD class="Heading14Bold" width="12%">Plate No</TD>
<TD class="Heading14Bold" width="10%">State</TD>
<TD class="Heading14Bold" width="19%">Vehicle</TD>
<td class="Heading14Bold" width="10%">Amount Due</td>
<td class="Heading14Bold" width="25%">Payment Amount</td>
</tr>
<tr >
<td> S123456 </td>
<td>09/27/2013 </td>
<td>123ABC </td>
<td>Wisconsin </td>
<td>Standard Passenger Car Plate </td>
<td>
$55.00
</td>
<td>
<input type="radio" name="p_S123456" value="BalanceDue" >Balance Due ($55.00)<br>
<input type="radio" name="p_S123456" value="Other" >Other $<input name="pOther_S123456" id="pOther_S123456" type="text" maxlength="14" size="10" />
</td>
</tr>
<tr class="backgroundLight">
<td> S123457 </td>
<td>12/08/2013 </td>
<td>123ABC </td>
<td>Wisconsin </td>
<td>Standard Passenger Car Plate </td>
<td>
$20.00
</td>
<td>
<input type="radio" name="p_S123457" value="BalanceDue" >Balance Due ($20.00)<br>
<input type="radio" name="p_S123457" value="Other" >Other $<input name="pOther_S123457" id="pOther_S123457" type="text" maxlength="14" size="10" />
</td>
</tr>
<tr>
<td colspan="2">Email Address: <span class="RequiredLabel">*</span> </td>
<td colspan="5">
<input type="text" name="email" size="35" maxlength="50" value="">
</td>
</tr>
</table>
<div align="center" style="margin-top: 8px;"><input type="submit" name="ticketPayments" value="Continue"></div>
</form>
<!-- InstanceEndEditable -->
</td>
</tr>
</table>We see that each discrete piece of data about each ticket is contained in a table cell <td>, and that each of these is the child of a <tr> that stands for each ticket. To get each ticket, we’ll figure out what is common to those <tr>s.
Each is the direct child of a form. Since there’s only one form on the page, we can start there. Note that XPATH requires some strict syntax and won’t necessarily follow the design of your element nesting here.
Here’s the XPATH syntax that finally worked to return each ticket and nothing else:
tickets = tree.xpath('//form/table/tr[position()>2]//td//text()')Here’s how we read this, from right to left:
- //text()
- Two slashes: Select ALL of
- text() - Select the text inside this element (as opposed to the class, or the href, or another attribute)
- //td - Select ALL <td> elements (even if they’re not the direct child)
- /tr[position()>2] - This is the complicated one. Select
<tr>s that are the direct children of the parent (one slash). Only select<tr>s that are the 3rd or greater<tr>child of their parent. This is to accommodate for these two<tr>s in our page that come before the tickets:
<tr>
<td colspan="7" class="RequiredLabel"><br>(* indicates required field)<br><br></td>
</tr>
<tr class="backgroundMedium">
<td class="Heading14Bold" width="12%">Ticket No</td>
<TD class="Heading14Bold" width="12%">Date of Violation</TD>
<TD class="Heading14Bold" width="12%">Plate No</TD>
<TD class="Heading14Bold" width="10%">State</TD>
<TD class="Heading14Bold" width="19%">Vehicle</TD>
<td class="Heading14Bold" width="10%">Amount Due</td>
<td class="Heading14Bold" width="25%">Payment Amount</td>
</tr>- //form/table - Select tables that are the direct children of ALL forms on the page.
Whew.
This give us (semi) nice lists like:
[' S123456 ', '09/27/2013 ', '123ABC ', 'Wisconsin ', 'Standard Passenger Car
Plate ', '\r\n\t\t\t\t\t\t\t\t\t$65.00 \r\n\t\t\t\t\t\t\t\t', '\r\n\t\t\t\t\t\
t\t\t\t\t', 'Balance Due ($65.00)', 'Other $', ' S123457 ', '12/08/2013 ', '123
ABC ', 'Wisconsin ', 'Standard Passenger Car Plate ', '\r\n\t\t\t\t\t\t\t\t\t$
30.00 \r\n\t\t\t\t\t\t\t\t', '\r\n\t\t\t\t\t\t\t\t\t\t', 'Balance Due ($30.00)'
, 'Other $', 'Email Address: ', '*', '\t', '\r\n\t\t\t\t\t\t\t\t']There’s a lot of garbage in there, like carriage returns, tabs, and spaces. Additionally, we’re only interested in some of the list elements:
#Strip out extra spaces, newlines, tabs.
#For each of these characters, replace itself with null in every element in tickets.
#Redefine tickets as this new string-replaced list.
chlist = ['\n','\r','\s','\t']
for ch in chlist:
tickets[:] = [s.replace(ch,'') for s in tickets]
#Build a dictionary, d. Parse the list of all tickets, organize them ordinally in a dictionary.
#Each dictionary entry will be a list. Pop the first 9 values off of tickets and create a new dictionary entry.
#Take the new tickets list and pop the next 9 values. Iterate until the list is too small to possibly contain a ticket (less than 4 elements long)
d = {}
i = 0 #Counter
while len(tickets)> 4:
d[i] = tickets[:9]
tickets = tickets[9:]
#Increment the counter
i = i + 1
#Neatly printing our output:
#Define our output template
template = '''Ticket No: %s
Date of Violation: %s
Plate No: %s
State: %s
Vehicle: %s
Amount Due: %s'''
# For each entry in the dictionary, replace the template with the real values and insert a new line.
for t in d.values():
results += template % (t[0],t[1],t[2],t[3],t[4],t[5]) + '\n\n'
print resultsApart from the neatly printed output, we also now have a dictionary of tickets. We’ve achieved the goal of a fake ‘API’ for searching for parking tickets.
Stay tuned for actually paying them.